How to migrate a cluster in production


One of the most complex operations in tech is upgrades or migrations without disrupting the service. I always compare it to upgrading a plane when it is flying.
Last year we faced a problem: Docker Swarm (Community) seems stalled. Besides, autoscaling and other tools that other container clusters provide out of the box are very manual.
Our setup at that moment was:
- Docker Swarm cluster
- ~50 Spring Boot services running on that cluster
- Deployed on AWS EC2
- API access via Application Load Balancers
- Every service was mapped to a Target Group
- No discovery service: We use hostnames to find the services internally.
There are many ways of deploying a microservice architecture. This is the simplest we found, and it worked like a solid rock for 5 years. This is what it looks like:
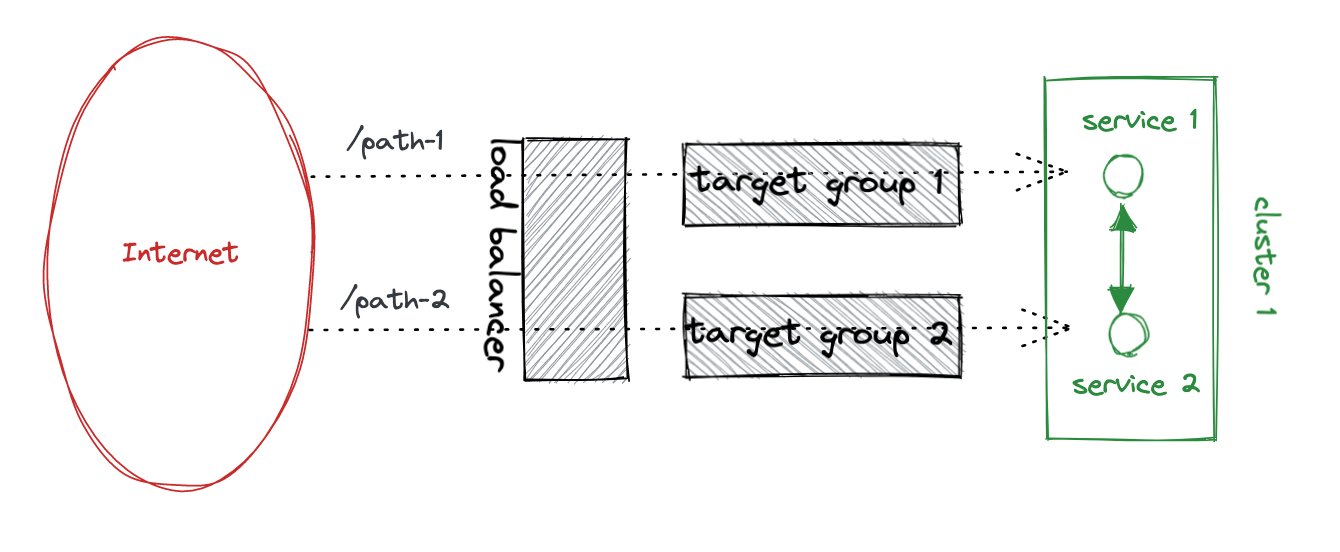
As you can see, Internet traffic comes from a Load Balancer. Traffic between services is internal. As part of the internal traffic, there is an event platform (Kafka).
Now that I think about it twice, it probably looked more like this:
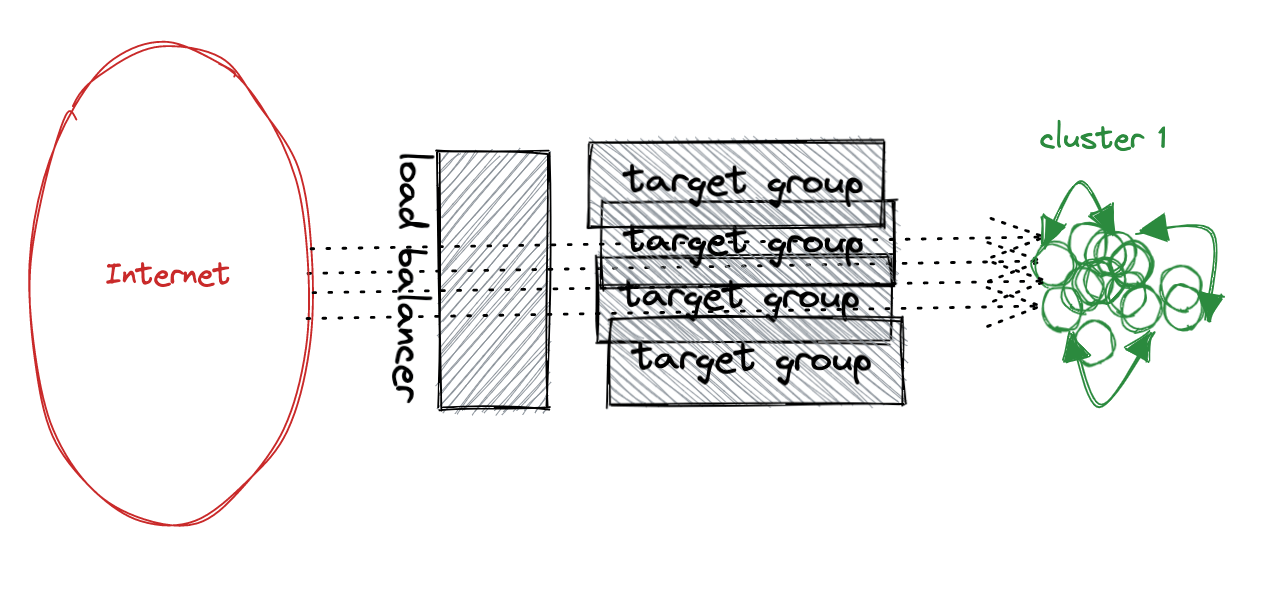
For our new cluster, we wanted something standard and, preferably, managed. So we decided to move out to EKS (the managed Kubernetes service on AWS). The problem is not writing the new descriptors to deploy on Kubernetes. The hard part is how to migrate the platform without stopping the service.
We could define a maintenance window in the early morning for a few hours, do the switch, and continue. But that process is stressful and very error-prone. What happens if we find an error? Rollback? Go forward? So we decided to do it progressively. It would be longer but safer. And we would learn a lot.
In summary, we saw two options:
- Set up the new architecture in the new cluster and do the switch: faster but harder to do without errors and stopping the service.
- Migrate service step by step: slower but safer. No need to stop the service.
How to connect two clusters
There are two common points for all the services in our architecture: the gateway (the load balancer in our case) and the data stores (sql, mongodb, kafka, …).
If we start a service in the cluster, we need to consider that:
- It might receive traffic from the Load Balancer.
- It might receive events from Kafka.
- It might call other services that… might not be in the same cluster.
If you have a discovery service, you could set up both clusters in reachable networks and register the services in the same discovery service. But we do not have such a piece.
The only way is to pass all the http traffic through the load balancer and split the traffic into both clusters. The load balancer will be our on/off switch. Drawbacks:
- it is a bit slower compared to the internal traffic (although nothing critical on our setup)
- more expensive, as AWS charges for the traffic handled by the load balancer.
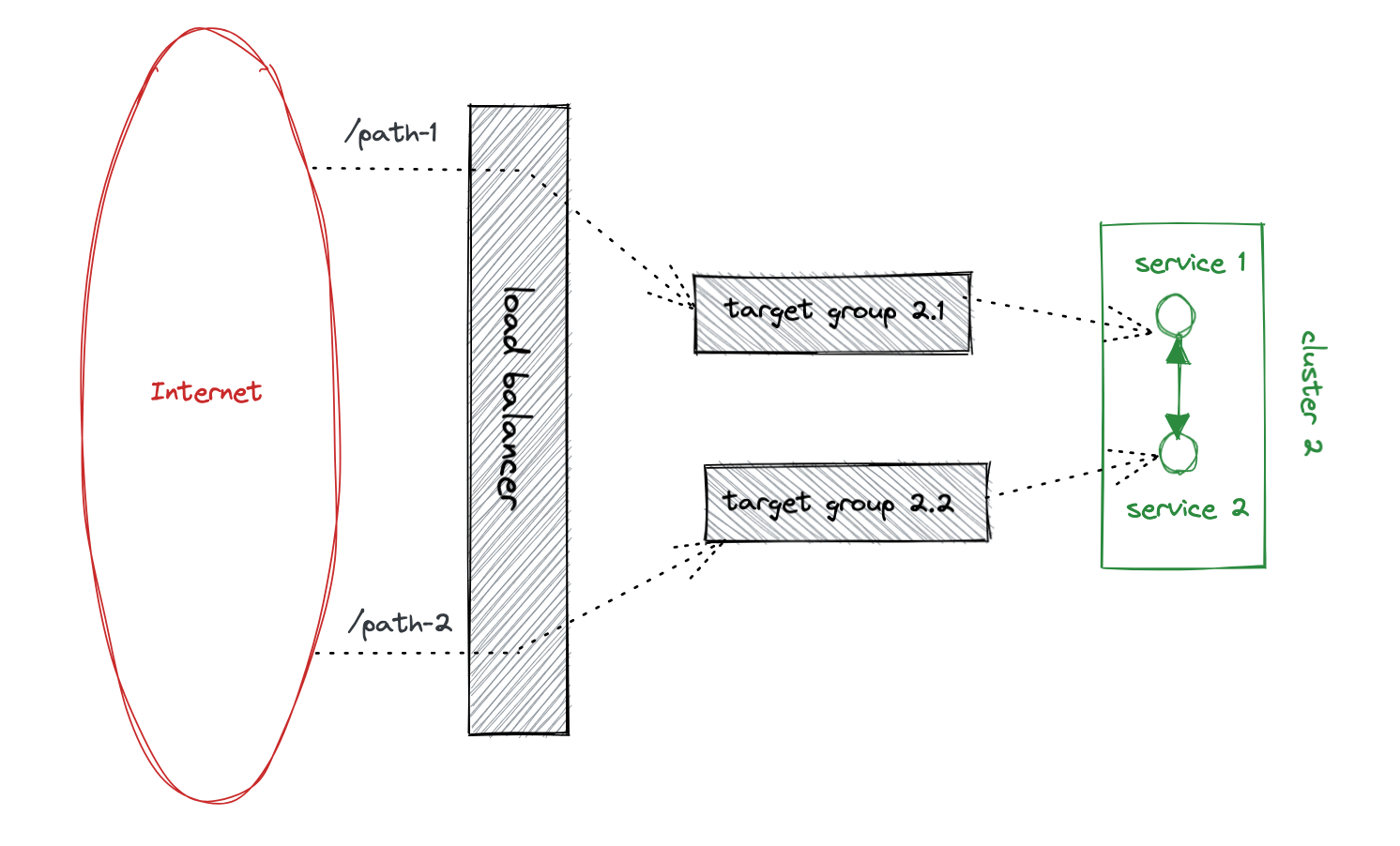
So this is the setup during the migration:
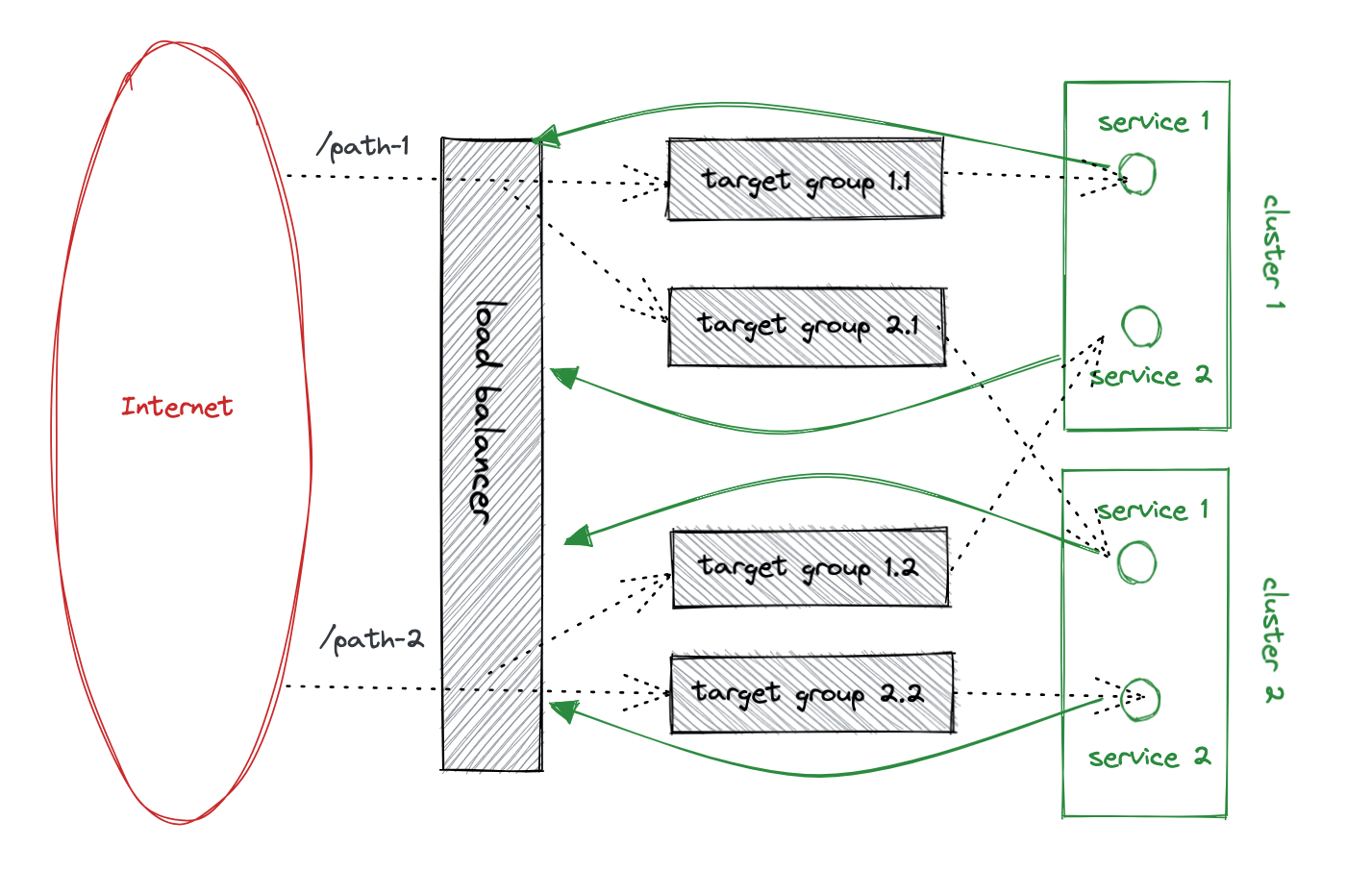
One target group per service and cluster. The load balancer splits the traffic into those target groups (the dotted lines). Services call each other going through the load balancer (the green lines). That allows us to control what services are deployed on the new cluster.
When every service is running on the new cluster, then we can stop the traffic to the old one:
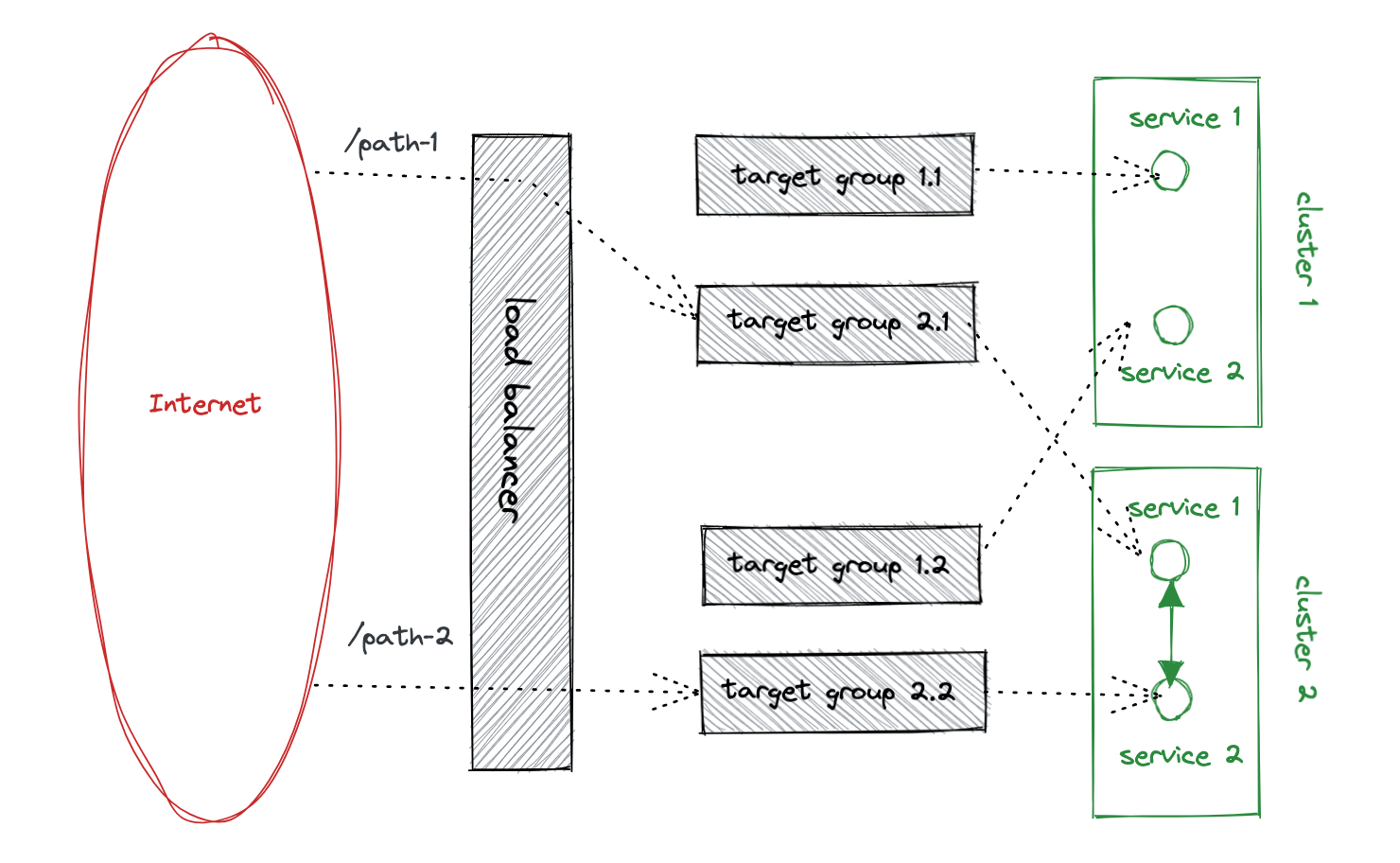
Again, as the traffic is controlled on the load balancer, we can stop services on our previous clusters while removing access from the load balancer.
And finally, we could delete all the components related to our previous cluster:
That is, we removed the mapping on the load balancer. That allowed us to delete the previous cluster completely. On the new cluster, we restored the internal traffic. Profit!
Conclusions
The plan was sound and easy to follow.
The only drawback that I see is the number of manual steps we needed to perform:
- Move the internal traffic to the load balancer (one change in every service).
- Deploy the service on the new cluster.
- Create new target groups and map them on the load balancer.
- Split the traffic to both target groups for every route mapped.
- Check that the service behaves as expected.
- Remove the previous load balancer.
- Move the traffic back from the load balancer to the cluster.
Some of the steps were mostly automated on our CI+CD pipeline (deployments, creation of the target groups, etc.), but some required us to work with the AWS CLI / Web console.