Denormalizing the core of Playtomic


Yes, another post about optimization and MongoDB. I started this post in July, and I couldn’t find the time to finish this. I was optimizing something O:)
Our core product at Playtomic is what we call Matches. A match is an entity that represents when, where, and who plays a game. That is the date and time, the location, and the players.
That data structure is stored in a MongoDB collection. At the moment I am writing this, that collection stores 27M documents and takes 100GB of data, 32GB of disk, and 14GB of indexes. It’s one of the biggest collections that I have managed in a transactional system consumed online by thousands of users at the same time (we have 800k active users).
At Playtomic, there are two main types of users: players and clubs. Broadly speaking, players want to find people and book a court. Clubs want to manage their courts and occupancy.
Focusing on matches again, that collection is both consumed by players and clubs in several ways:
- Players looking for matches to join.
- Players checking their history.
- Players uploading results.
- Clubs checking their current schedule.
- Clubs checking their history.
This is a screenshot of what you can find on Playtomic’s application:
As you can imagine, there are many access patterns to that collection. For example, I can search matches that I can join filtered by
- club
- location (coordinates)
- my levels
- number of players
- court type (indoor vs outdoor, materials of the walls, …)
- gender of the players
And if I cannot join due to some restrictions, I can request to join and wait for the approval of the rest of the players. I don’t want to bore you, but as I said, there are too many ways to access the same data.
There is only one way to make those queries efficient: indexes. But indexes come with a cost:
- The more indexes you have, the slower the modifications are (insertion, update, or deletes).
- Those indexes must be in memory to be efficient: more indexes, more memory needed.
- As the collection grows, changing or creating indexes becomes a delicate matter: you must read the whole collection to create it. In a production system, that might entail problems if you are already overloaded.
Our product grew fast and in a slightly chaotic way. We had many indexes that covered the most common queries, but we could not have an index for every combination of parameters we allowed in our search. And thus, this happened:
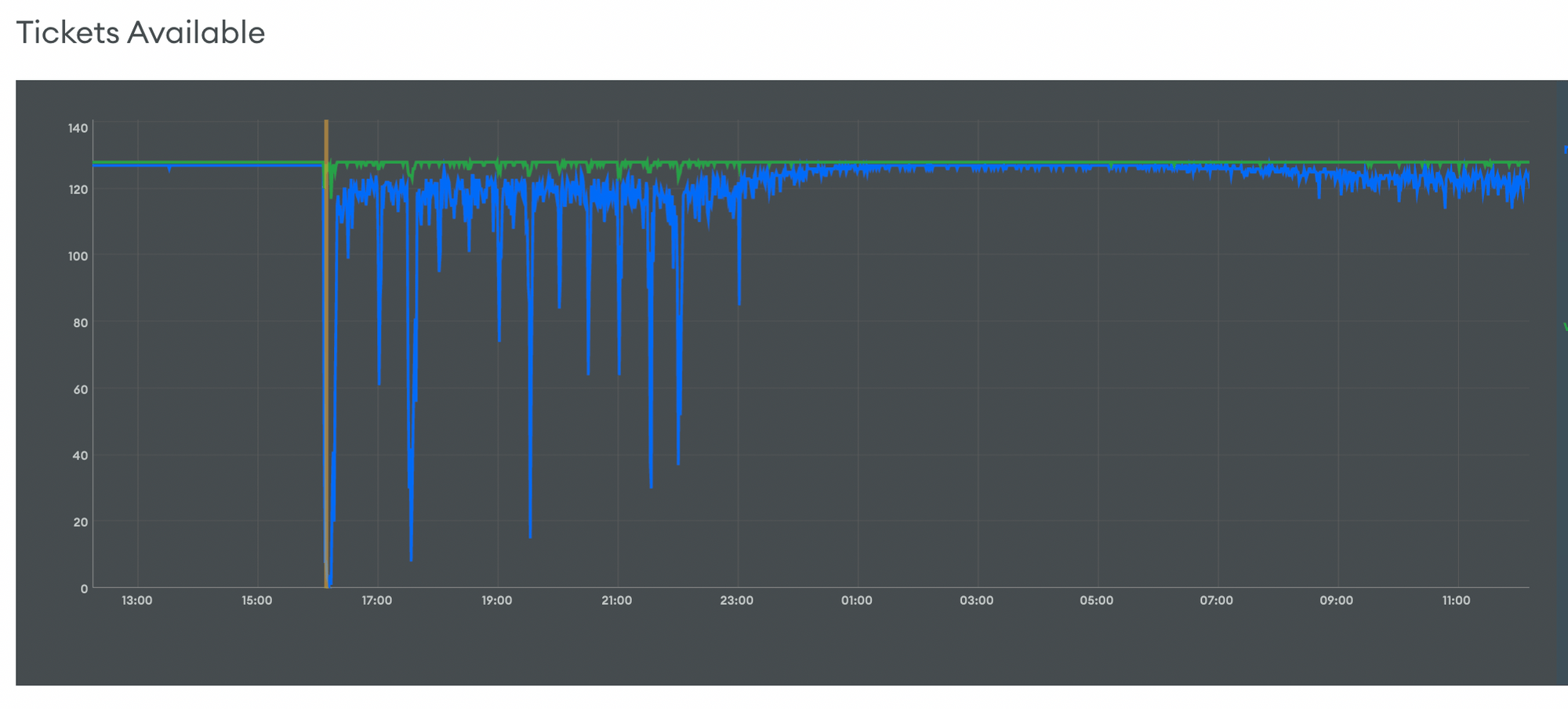
In summary: we were dead. MongoDB had not enough resources to reply.
When we received many queries at the same that were not fully covered by our indexes… MongoDB suffered. Remind that our collection was 32GB on disk. If you want to read more about MongoDB Performance, I wrote a post about it in February.
We needed a fast solution that didn’t require completely reworking the API we were exposing. We realized something: the most complex patterns were always to find public matches in the near future. A public match means that everyone can see and search for those matches. Private matches are not searchable.
This was the idea: to denormalize that data into a new collection. The source of truth would still be the original collection. We would only have the data that we need to feed the indexes, the rest of the data is not there. We apologized to all the teachers that taught us the 3rd normal form at college and then we got our hands dirty.
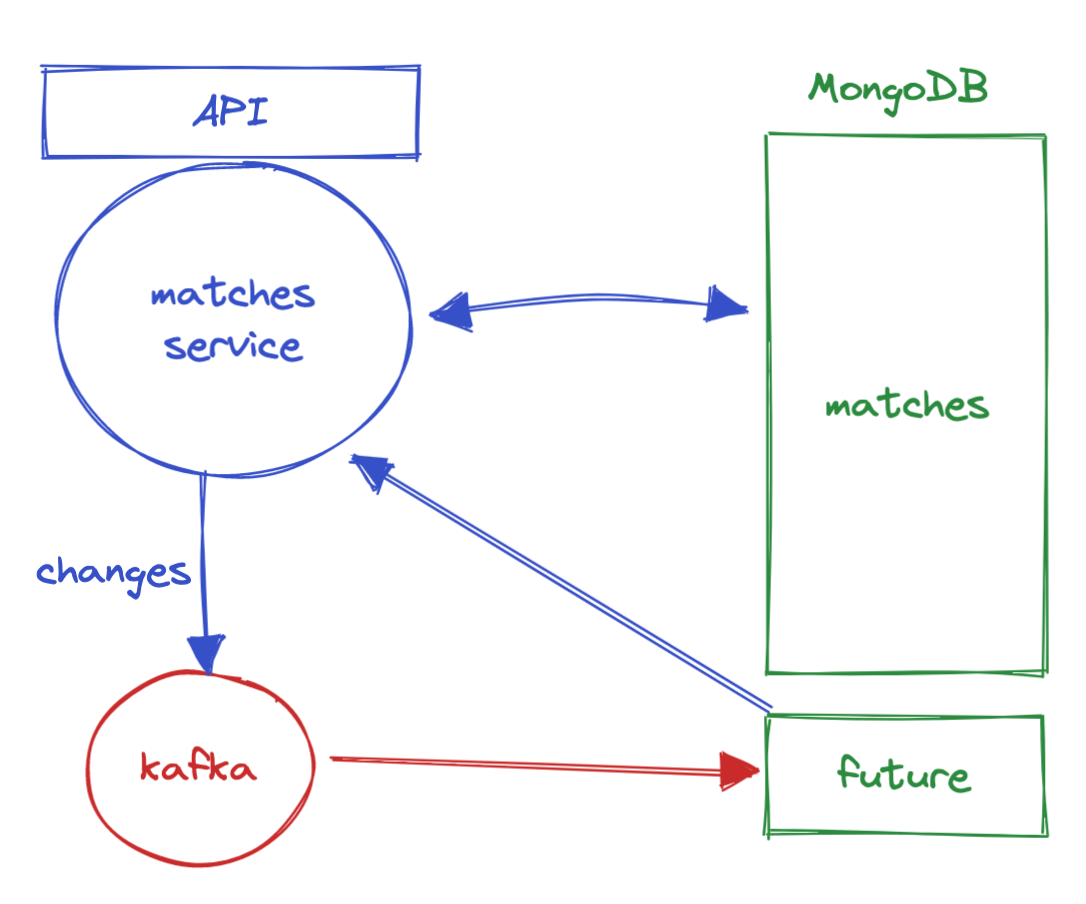 Luckily all our platform was already event-driven, so we could update that denormalized collection via Kafka events. Data would expire using TTL indexes.
Luckily all our platform was already event-driven, so we could update that denormalized collection via Kafka events. Data would expire using TTL indexes.
Our clubs generally allow opening public matches within 2-3 weeks. That means that we keep between 14 and 21 days of data. We allow players to upload their public matches, but their number is still below the number of matches that clubs manage.
To be sure that we are always returning the most recent data, we use the $lookup command to read at the final step the last version of the match in the original collection.


New collection: 7.7k documents, 5.30MB of data (!!), and 2.25MB on indexes.
I dont’t keep the screenshot of IOPS and Tickets Available after we made the change, or the reduced latency we experimented with in our API, but the improvement was huge.
Since then, this is how our Tickets Available chart looks:
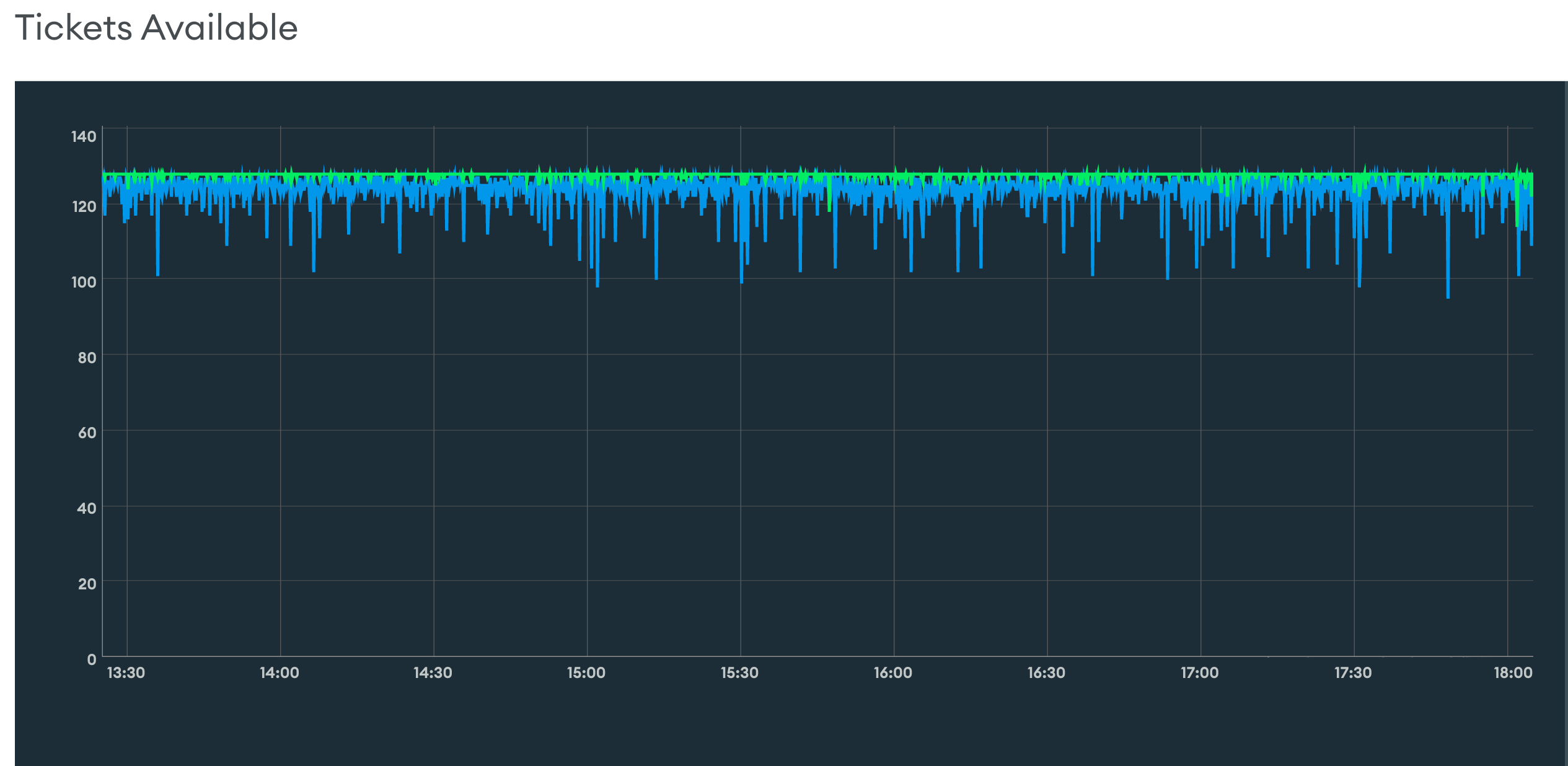 Still not 100% perfect, but much better than we were before!
Still not 100% perfect, but much better than we were before!